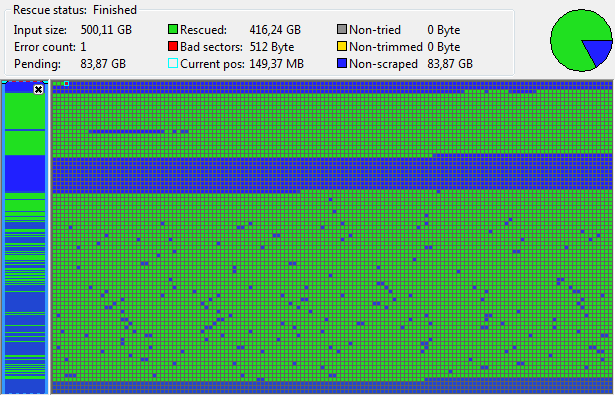
416,24 GB wiederhergestellt, aber knapp 84 fehlen noch. Hm, das ist ungewöhnlich schlechte Ausbeute, vor allem weil so große Blöcke fehlen. Da muss ich etwas falsch gemacht haben.
Ich höre schon meine alte Ausbildungskollegin schreien „manpage, MANPAGE!!!“
ddrescue läuft mit den Parametern (Reihenfolge zu Dramaturgiezwecken geändert)
-f -r10 -v -n
-f: force overwrite of outfile, braucht man, wenn auf eine Partition geschrieben wird
-r10: Exit after the given number of retry passes
-v: Verbose mode
-n: Skip the scraping phase
Vielleicht sollte ich das letzte weglassen 😉
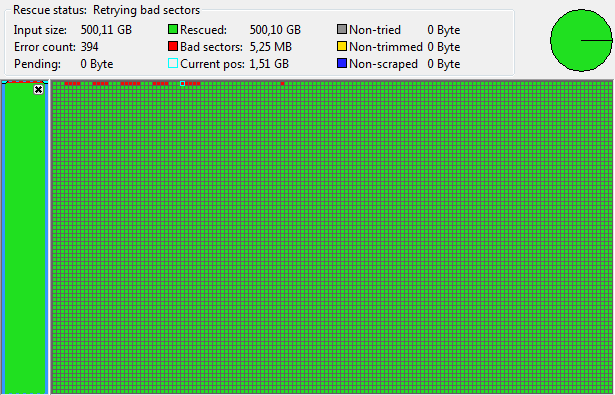
Gesagt, getan – und ddrescue läuft weiter. Im Schleichmodus werden die restlichen Daten zusammengekratzt. Um diese Schleichfahrt nicht zu blockieren, habe ich den Knockout meines Scripts auf 2 Stunden gesetzt. Nach ein paar weiteren Tagen sieht es wie folgt aus:
Das würde ich als Erfolg bezeichnen. Mit dem Hintergrund, dass die erste Partition der Platte eine versteckte EFI-Partition mit 200 MB ist, sollten die Userdaten vollständig lesbar sein.
Das Volume ließ sich dann auch wieder mounten. Um auf Nummer sicher zu gehen, habe ich aber trotzdem noch ein Image der Partition gezogen.
macht den Job. Wichtig ist, die Blocksize anzugeben, da sonst gefühlt Byteweise kopiert wird und so der Durchsatz unterirdisch ist – ohne Parameter dümpelte der Kopiervorgang von USB 2.0 nach USB 2.0 mit 4 MB/s herum, mit 64K bei 38 MB/s. Mehr geht über die Schnittstelle fast nicht.
„Nein“ wäre die richtige Antwort gewesen. „Nein“ zur Frage, ob ich eine Festplatte wiederherstellen kann, die vor meinen Augen nochmal fallen gelassen wurde.
„Macht der das was?“
JA, verdammt nochmal – Festplatten (also „klassische“ mit Magnetscheiben) sind mechanisch empfindliche Komponenten.
Naja. Eine zweite Platte für die Wiederherstellung hat er immerhin schon besorgt, also versuche ich mein Glück. Also ein Live-Linux in das olle Thinkpad geworfen und ddrescue gestartet.
Quelle: 500 GB 2,5 Zoll Western Digital Blue, Ziel: 1 TB 2,5 Zoll Seagate.
Zunächst ging es auch ordentlich schnell und ich dachte, der begrenzende Faktor wäre das USB 2.0 am Rechner. Doch auch mit der extra georderten USB 3.0 Expresscard ging es nach ein paar Klimmzügen (zusätzliche Versorgung der Festplatten) nicht wirklich schneller.
Nach den ersten paar Gigabyte sackte die Leserate aber auf mehrere 100 kByte/s ab. Nicht so schlimm, wäre da nicht folgendes Geräusch:
(das nach 10 Sekunden)
Wäre da nur das Geräusch, könnte man vielleicht noch damit leben, aber ddrescue macht nur noch eines: Fehler für Runde zwei melden. Das bringt einen nicht weiter. Also Platte weg und wieder ran. Die ersten paar Stunden mache ich das noch manuell, dementsprechend haben sich knapp 100 GByte Lesefehler und ein wenig Frustration angesammelt. Grmpf. Dabei fiel auf, dass die ersten 30 Sekunden die Übertragungsrate mit 15-30 MByte/s noch relativ hoch war, danach sank sie schlagartig ab und schwankte zwischen 65 und 300 kByte/s.
In einer Woche (Abends, musste in der Nähe sein) kamen so etwa 90 GByte von Platte A auf Platte B. 150 GByte wurden als nicht lesbar markiert.
Um nicht dauernd den USB-Stecker ein- und ausstecken zu müssen, habe kam eines meiner Schubladen-Projekte zum Einsatz, der (verbuggte) USB-Switch. Mit einem Mit einem TS3USB221 (sehr klein und bescheiden zu löten) und einem IRLML2244 lässt sich das angeschlossene Device mit dem PC verbinden und trennen. Die Verbindungsfolgen werden erwartungsgemäß nicht eingehalten und durch einen Denkfehler und zu wenig Koffein schaltete die aktuelle Version entweder die Versorgung oder USB durch. Fädeldraht hat es zumindest vorübergehend gerichtet. Mit einem Schalter ausgestattet bleiben nun die Stecker heile.
Aber zurück zur Datenrettung. Zwei Gedanken: Die Platte alle 30 Sekunden pauschal zu trennen erhöht zwar die Datenrate, aber auch die elektromechanischen Zyklen, was der Lebensdauer nicht wirklich zuträglich ist. Gleichzeitig kommt die Platte nach einem Aussetzer nicht mehr hoch. Sie muss neu gestartet werden. Das kann man überwachen, indem man die Größe der Logfile von ddrescue prüft. Wächst diese stark an, ist etwas im faul. Ferner beendet sich ddrescue automatisch, wenn die Platte sich komplett abwirft.
So viel zum Wissen, aber wie kommt diese Information zum USB-Switch? Am einfachsten wäre es ja, den USB-Port selbst aus- und wieder einzuschalten. Geht in manchen Systemen, aber eine mittelkurze Recherche zeigte: die Erfolgschancen sind eher gering.
Also doch irgendwie anders. Hm. Der Laptop ist zu jung für den Parallelport, einen Microcontroller dafür zu programmieren ist mir ehrlich gesagt auch zu blöd. Hm, DTR und RTS lassen sich doch üblicherweise durch Software schalten und einen USB<>UART-Wandler, bei dem zumindest RTS herausgeführt ist, liegt auch herum.
Unter Linux ist doch alles eine Datei, also sollte es doch ein Leichtes sein, das Flag zu setzen. Leider nicht ganz. ioctl macht zwar genau das, aber es ist nicht persistent. Sobald das Programm sich beendet, wird der Port geschlossen und RTS/DTR ist wieder low. über stty schafft man es zwar auch irgendwie, aber mein Shell-Script begann eh anfangen, ziemlich übel zu stinken.
Nachdem desinfec’t mit Python kommt – warum nicht damit? Mit pyserial kann ich zumindest unter Windows schon einmal alles machen, unter Linux klappt es auch auf Anhieb.
Mittlerweile sieht das Setup so aus:
Die Platte liegt (ich weiß, nicht ganz ideal) auf einer Schütte, der Lüfter hält sie kühl. Am Notebook hängt der USB-Stick mit Scripts und Log (wichtig, da im Notebook kein persistenter Speicher ist), daneben der USB-Switch, der mit dem RTS des USB<>UART-Wandler verbunden ist.
Das Python-Script macht aktuell folgendes:
Verbinden der Platte und warten, bis /dev/sdx (also die Platte) existiert. ddrescue mit den entsprechenden Parametern als subprocess starten. Während es läuft, also .poll() des Prozesses keinen Exitcode ausweist. Weiter wird geprüft ob die Logdatei anschwillt. Dank Caching ist das leider nicht ganz so zielführend, aber immerhin. Das dritte Kriterium ist die Laufzeit. Ist die Datenrettung länger als 10 Minuten aktiv, naja – ich bin nicht stolz drauf. Tritt eine der drei Bedingungen ein, wird die Platte getrennt und gewartet (falls nicht schon passiert), bis ddrescue fertig mit dem Schreiben der Logdatei ist. Nach einer weiteren Wartezeit geht das Spiel von vorne los:
rescue.zip (weil WordPress mir Python-Scripts verbietet)
Für Schäden, die das Script verursachen kann, übernehme ich keine Haftung.
In nicht ganz 24 Stunden sind so nun weitere 130 GByte in Richtung Ersatzplatte gewandert. „Nur“ 35 weitere Gbyte wurden als defekt markiert.
Ob die Aktion erfolgreich gewesen sein wird, kann ich erst in knapp 280 GByte sagen und hoffe, dass auch so viel davon gelesen werden kann.
Abschließend kann ich nur mal wieder sagen: Kein Backup? Kein Mitleid!