Chip on Board-LED-Module – mittlerweile in Flutern sehr weit verbreitet und sehr günstig zu beschaffen.
Da ich bei einer Aufräumaktion eine Schreibtischleuchte (noch mit Leuchtstofflampen und fehlendem Treiber) ergattern konnte war der erste Gedanke: Umrüsten auf LED.
Im Asiamarkt (ok, eBay) gab es 4 Module – 2x warmweiß und 2x kaltweiß – für nicht ganz 6 Euro bei nicht einmal 2 Wochen Versand:

Leider sind Module mit 2700 K Farbtemperatur eher selten, also ca. 3250 K und 6250 K. Aber warum überhaupt verschiedene Werte? Kaltweiß ist besser, um Farben neutral zu sehen, warmweiß ist angenehmer für’s Auge. Allerdings muss man dazu sagen: es ist nur die halbe Wahrheit. Ein wichtiger ist der CRI. Echte weiße LEDs gibt es nicht, es handelt sich in aller Regel um blauen LEDs, die bestimmte Farbstoffe anregen und je nach Material ist das Spektrum und damit die Farbwiedergabe unterschiedlich – aber das nur am Rande.
Um die Spannung und Ströme der Streifen gering zu halten, sind die LEDs in mehrere Stränge, meist mit der Länge 3 angeordnet. Bei einer Flussspannung von 3,2 Volt sind das 9,6 Volt, mit einem Vorwiderstand haben die meisten Streifen eine Betriebsspannung von 12 Volt. Das ist bei den meisten COBs meist nicht der Fall. 4 LEDs in Reihe, mehrere dieser Stränge parallel und fertig. Durch Fertigungstoleranzen schwanken die Vorwärtsspannungen ein bisschen, das kann man im Griff haben aber das kostet natürlich. Bei einigen hundert LEDs für 6 Euro: never ever.
Aber wie schlecht sind sie wirklich? Der Test funktioniert relativ einfach: LED an eine Spannungsquelle anschließen und die Spannung so weit erhöhen, bis sie leicht zu glimmen anfangen – bei den gekauften Exemplaren war das bei 9 Volt:

Montage von 4 Fotos bei gleicher Belichtungszeit
Die Belichtung wurde so eingestellt, dass möglichst keine Übersteuerung der Farbkanäle stattfindet, hat auch fast geklappt.
Man sieht gewisse Ungleichmäßigkeiten, not too bad, not too good either. Richtiges Binning hat auf keinen Fall stattgefunden.
Die Leuchtpunkte der unteren LED wurden ausgeschnitten, ausgerichtet und durch ein kleines Python-Script (mit pillow statt pil) gejagt:
from PIL import Image
im = Image.open('P1120207.png', 'r')
width, height = im.size
pixel_values = list(im.getdata())
y = 8
for x in range(0, width):
px = pixel_values[width*y+x]
print(str(px[0]) + "\t" + str(px[1]) + "\t" + str(px[2]))
Das Script spuckt die RGB-Werte der 8. Zeile aus. Auch wenn der blaue Farbkanal am ehesten heraussticht, ist es besser den grünen zu verwenden – weniger Clipping und durch Chroma-Subsampling (besser kein JPEG verwenden) und des Bayer-Pattern ist grün einfach besser ;).
Aus Excel kam dann folgendes Diagramm: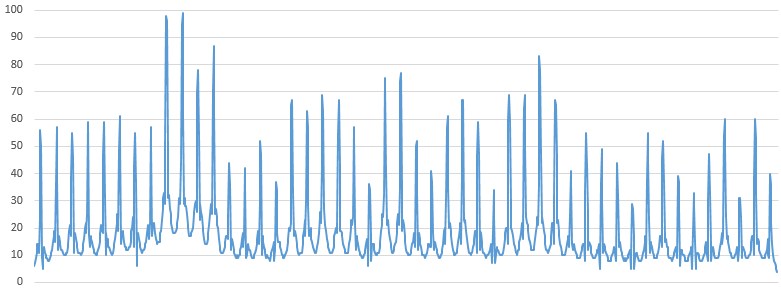
Mit ein bisschen Phantasie erkennt man die Stranglänge. Die Aussagekraft des Diagramms ist zugegebenermaßen etwas eingeschränkt: Es ist kein kalibriertes System sondern eher ein Schätzeisen aber es reicht für einen groben Vergleich: Es gibt einen ausreißenden Strang (nach oben) und einige LED-Chips in den Stränge, die deutlich darunter liegen. Grundlegend ist die Bewertung mit dem Diagramm aber etwas besser möglich als durch das Ansehen der Bilder, da der Faktor subjektive Wahrnehmung verringert wird und Nuancen in Helligkeitsunterschieden besser erkennbar sind.
Mal sehen, wie sich die Streifen dann im tatsächlichen Einsatz machen…