Hier werkelt seit knapp 5 Jahren eine Fritz!Box 7390. Mit Loch im Deckel und sehr langsam drehendem Lüfter erlitt sie bis jetzt noch nicht den Hitzetod und braucht daher sehr wenig Aufmerksamkeit.
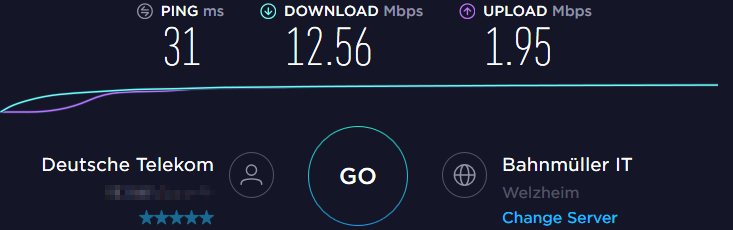
Leider ist das DSL hier nicht ganz so schnell, wie es mir lieb wäre. Ich klage zwar noch immer auf hohem Niveau, von den knapp 17,7 Mbit/s nutzt die Box 15,1 Mbit/s und es bleiben 12,56 Mbit/s für den tatsächlichen Download übrig. Im Upload sind es 2,8/2,3/1,95 Mbit/s:
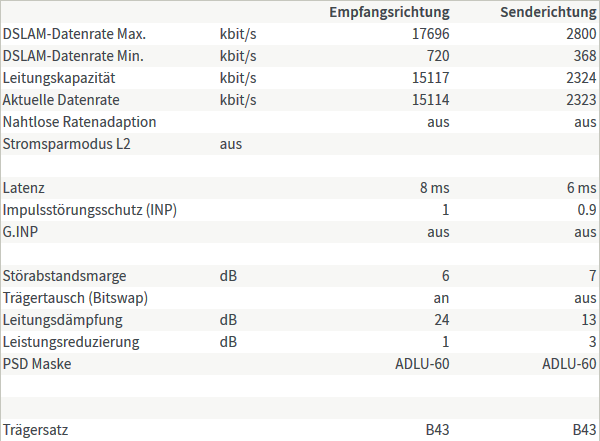
Weil sie dann doch etwas in die Jahre gekommen ist, und die 7390 nicht unbedingt durch ihre DSL-Performance bekannt wurde, wollte ich mir mal eine zweite Meinung einholen. Ok, eine ähnlich alte 7360 – aber mal einen Versuch wert.
Nach etwas Suchen wurde allerdings klar – und nun zum eigentlichen Thema: ich habe die für die Einrichtung benötigten Logindaten verlegt. Mist.
Also mal suchen, wie man die Daten da herausbekommt. Das auf vielen Seiten beworbene Tool RouterPassView von Nir Sofer (der schnörkellose und sehr gute Tools anbietet) funktioniert nicht (mehr?) mit Fritz!Boxen.
Eine andere Lösung: Die fb_tools von Michael Engelke. Der in der Beschreibung gezeigte Befehl führte bei mir nur zu folgender Ausgabe:
Keine Konfig erhalten - Möglichlichweise ist noch die Sicherheits-Bestätigungsfunktion aktiviert? [sic!]
Also in der Anleitung der Box nachgeschaut – unter System -> FRITZ“Box-Benutzer -> Anmeldung im Heimnetz lässt sich die Option Ausführung bestimmter Einstellungen und Funktionen zusätzlich bestätigen zwar deaktivieren, nach dem Übernehmen ist die Option allerdings wieder gesetzt. Hmpf.
Wenn das Script die Daten aber entschlüsseln kann und die man in der Box die Einstellungen speichern kann – AVM wird wohl kaum mehrere Verfahren für die Crypto der Konfiguration verwendet haben. Schaut man etwas genauer in die Hilfe der fb_tools – ja, es kann verschlüsselt gesicherte Exportdateien entschlüsseln. Mit
fb_tools.bat nix@nix konfig File-DeCrypt sicherung.export dateipasswort
bekommt man die Daten direkt in der Konsole (Anm: das Tool braucht für den Aufruf immer Passwort@IP, nix@nix funktioniert auch, da kein Zugriff auf die Box erfolgt):

Jetzt muss man nur noch wissen, wie der „internet-String“ aufgebaut ist. Aus DFÜ-Zeiten weiß man noch:
Anschlusskennung#Zugangsnummer#Mitbenutzernummer@t-online.de
Das Password steht direkt hinter passwd= und war zumindest bis vor ein paar Jahren eine 8-stellige Nummer.
Auf die Test-7360-Box eingetippelt und eingestöpselt, purzeln auch hier die Bytes durchs verdrillte Kupfer. Die Ergebnisse sind etwas besser aber trotzdem ernüchternd:
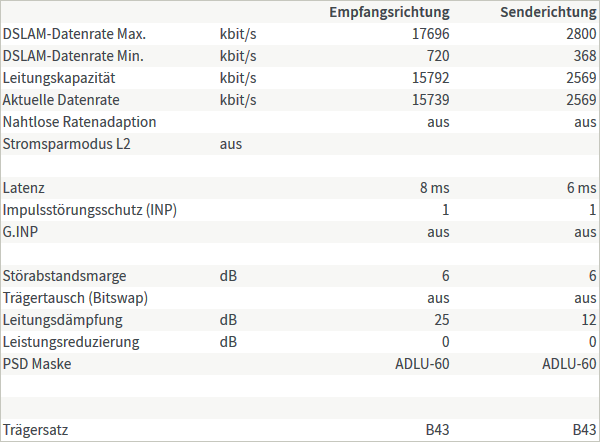
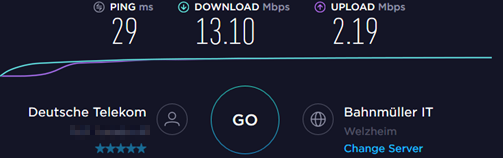
Die Frage, wie sich die Performance bei einem moderneren oder etwas besseren Hardware verhält, bleibt natürlich offen. Unterm Strich: für die meisten Anwendungen reicht das. Auch wenn der Outdoor-DSLAM von m-net nur 70 m weiter steht, mit einer IPv4 wäre es dort um die 5 Euro im Monat mehr. Mehr Upload wäre gerade für VPN toll, aber die Schmerzen sind dafür nicht groß genug 😉